# Devenir Dynamique
La seconde partie du didacticiel est disponible en video ici:
Ces deux pages sont plutôt sympas, mais un blog sans article c'est tout de même un peu léger! Travaillons sur ce point à présent.
Pour les besoins de ce didacticiel, nous allons récupérer nos articles depuis la base de données. Puisque les bases de données relationelles sont encore aujourd'hui au coeur de beaucoup d'applications complexes (ou moins complexes d'ailleurs), nous avons fait en sorte de réserver un traitement de première classe aux accès SQL. Dans une application Redwood, tout part du schéma.
# Créer le schéma de la base de données
Nous devons identifier quelles données seront nécessaires pour un article. Plus tard nous ajouterons d'autres éléments, mais pour commencer nous avons besoin de ceci:
ìdl'identifiant unique pour un article (chaque table de notre base de données aura également un identifiant tel que celui-ci)titlele titre de l'articlebodyle contenu de l'articlecreatedAtun 'timestamp' correspondant au moment où l'article est enregistré dans la base de données
Nous utilisons Prisma Client JS pour parler vac la base de données. Prisma possède aun autre librairie, appellée Migrate, qui nous permet de mettre à jour le schéma de la base de données en capturant chaque changement successif. Chacun de ces changement est appelé migration, et cette librairie Migrate en créé un nouveau à chaque modification du schéma.
Tout d'abord, définissons la structure d'un article de notre blog dans la base de données. Ouvrez api/prisma/schema.prisma et ajoutez la définition de la table Post (supprimez au passage tous les modèles présents par défaut dans ce fichier). Une fois terminé, le fichier se présente ainsi:
// api/prisma/schema.prisma
datasource DS {
provider = "sqlite"
url = env("DATABASE_URL")
}
generator client {
provider = "prisma-client-js"
binaryTargets = "native"
}
model Post { id Int @id @default(autoincrement()) title String body String createdAt DateTime @default(now())}Cette série d'instructions signifie que nous voulons créer une table Post avec les éléments suivants:
- Un champ
idde typeInt, nous précisions à Prisma que cette colonne constitue un identifiant@id(de façon à pouvoir créer des relations avec d'autres tables) et que la valeur par@defaultcorrespond à la fonction Prismaautoincrement()impliquant que la base de données insèrera une nouvelle valeur automatiquement lorsqu'un enregistrement est créé. - Un champ
titlede typeString - Un champ
bodyégalement de typeString - Un champ
createdAtde typeDateTimeavec une valeur par@defaultégale ànow()pour chaque nouvel enregistrement (ainsi nous n'avons pas à nous en charger dans l'application, la base de données le fera pour nous)
Identifiant de type Integer vs. identifiant de type String
Pour le didacticiel, nous resterons simple et utiliserons un identifiant de type Integer. Ceci étant, une application plus évoluée pourra utiliser un identifiant de type CUID ou UUID. Tous deux sont pris en charge par Prisma. Dans ce cas, vous utiliseriez un champ de type
Stringau lieu deInt, etcuid()ouuuid()au lieu deautoincrement():
id String @id @default(cuid())Notez que l'utilisation d'un identifiant de type Integer permet d'obtenir des url plus simples comme https://redwoodblog.com/posts/123 instead of https://redwoodblog.com/posts/eebb026c-b661-42fe-93bf-f1a373421a13.
Allez voir la documentation officielle de Prisma pour plus de détails sur les champs identifiants.
# Migrations
Bon, la création du schéma : c'est fait! Maintenant ce que nous vonlons c'est capturer son état pour en faire une migration:
yarn redwood db save create posts
Ce faisant, vous venez de nommer votre première migration "create posts". Redwood ne tient pas compte de ce nom, mais il est recommandé de choisir un nom significatif pour les autres développeurs de votre équipe.
Une fois la commande exécutée, vous pourrez constater la création d'un nouveau sous-répertoire dans api/prisma/migrations avec un timestamp et le nom que vous avez donné votre migration. Ce sous-répertoire contient quelques fichiers: une capture du schéma de la base dans schema.prisma, ainsi que la suite de directives que Prima utilise pour effectuer les modifications dans steps.json).
Nous allons maintenant appliquer cette migration avec cette commande:
yarn rw db up
Raccourçi
redwoodDésormais, nous utiliserons dans nos commandes la forme courte
rwà la place deredwood.
L'exécution de cette commande permet à Prisma d'appliquer les changements sur la base de données, en l'espèce la création d'une nouvelle table Post avec les champs définis plus haut.
# Créer une Interface d'Édition d'un Article
Nous n'avons pas encore décidé du look de notre site, mais ne serait-il pas extra si nous pouvions commencer à manipuler nos articles de blog, commencer à créer quelques pages rapidement le temps que l'équipe chargée du design rende sa copie? Heureusement pour nous, "Incroyable" est le petit nom de Redwood :)
Générons tout ce sont nous avons besoin pour réaliser un CRUD (Create, Retrieve, Update, Delete) (Créer, Récupérer, Mettre à jour, Supprimer) sur nos articles. Redwood a justement un generateur spécialement fait pour ça :
yarn rw g scaffold post
Ouvrons la page http://localhost:8910/posts et constatons le résultat:
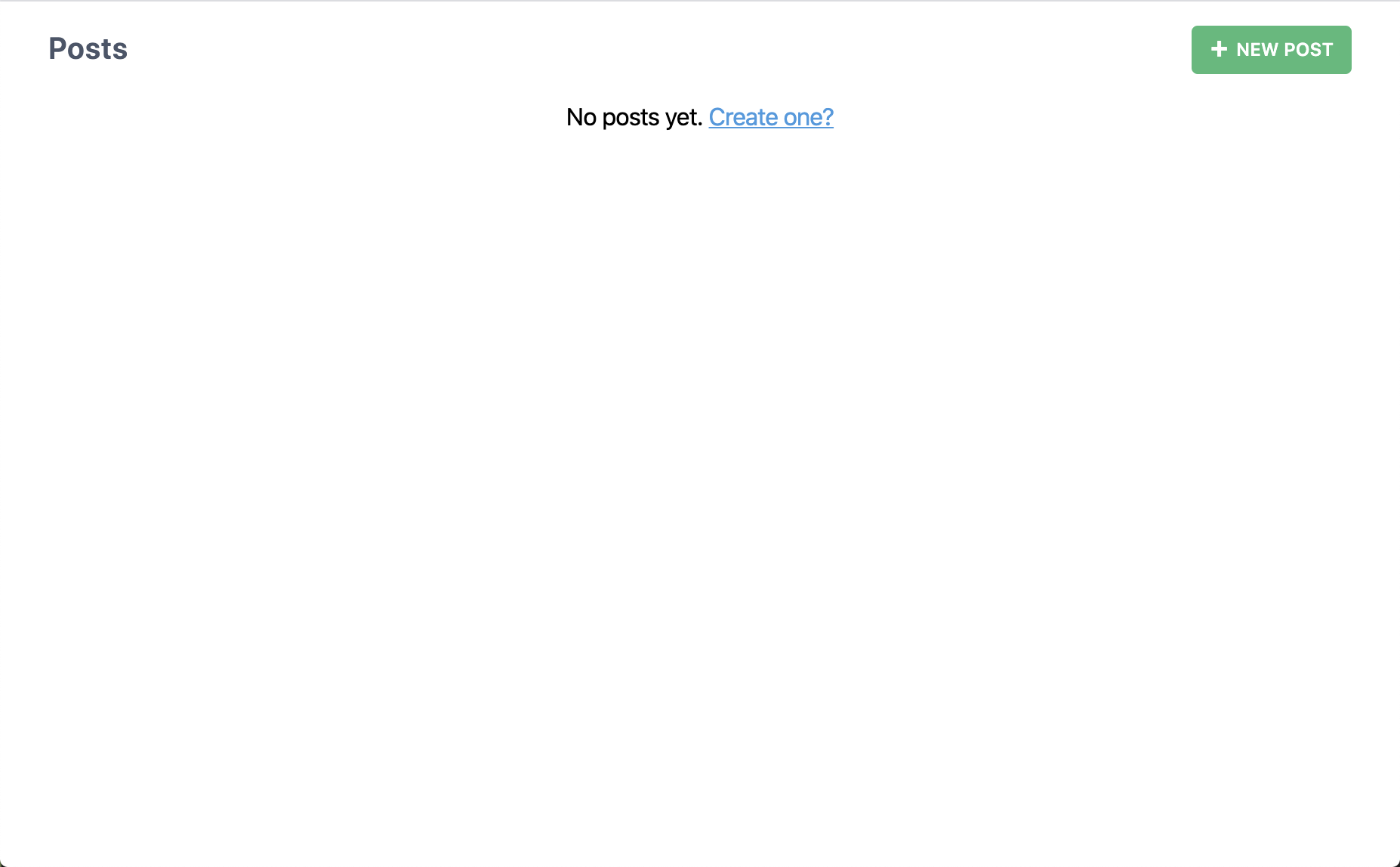
Humm.. ça n'est pas beaucoup plus que ce que nous avions obtenu losque nous avions créé notre première page. Que se passe-t-il lorsque nous cliquons sur le bouton "New Post" (Nouvel Article) ?
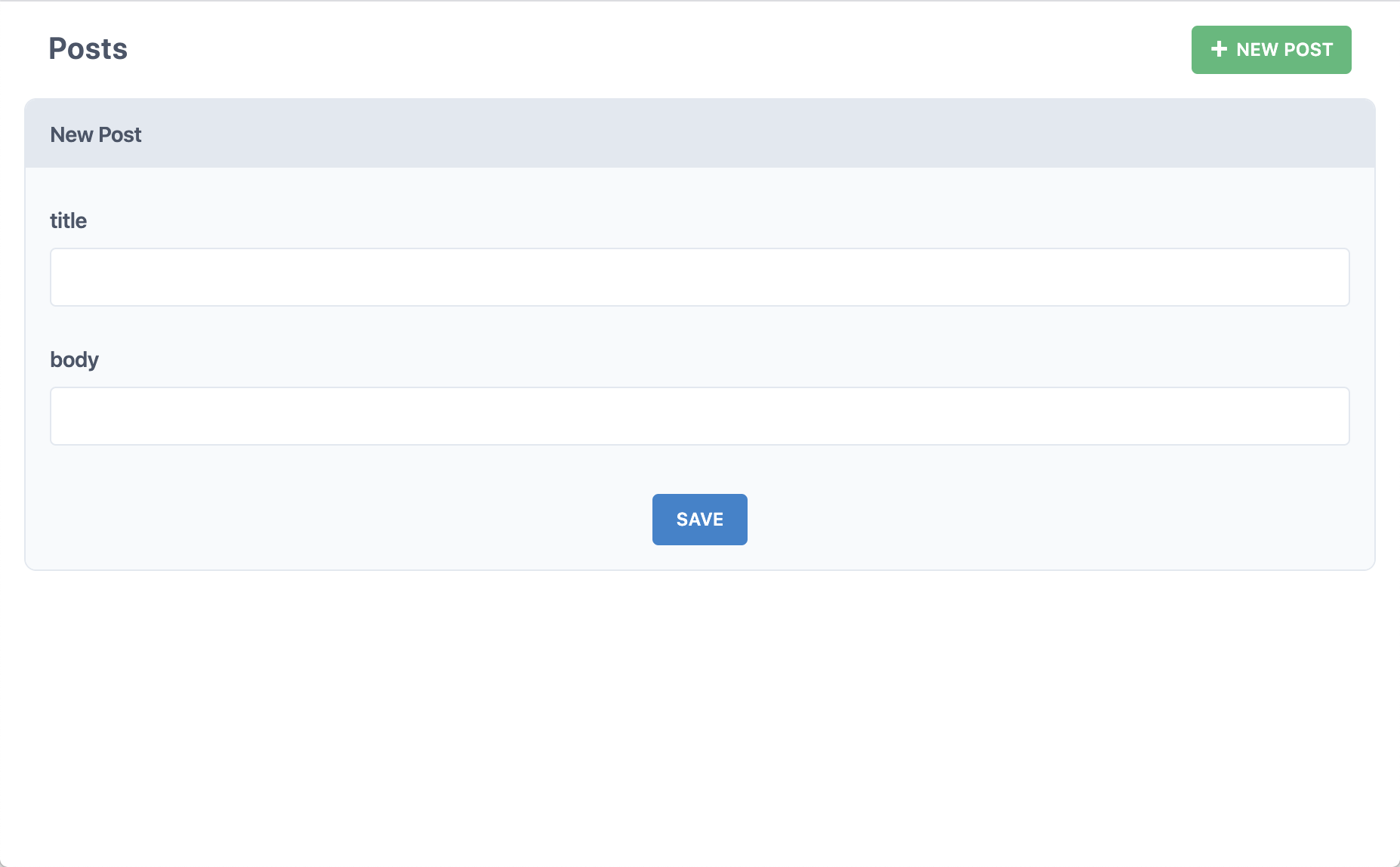
Ah, maintenant on commence à parler sérieusement! Remplissez donc les champs title (titre) et body (contenu), puis cliquez sur "Save" pour enregistrer.
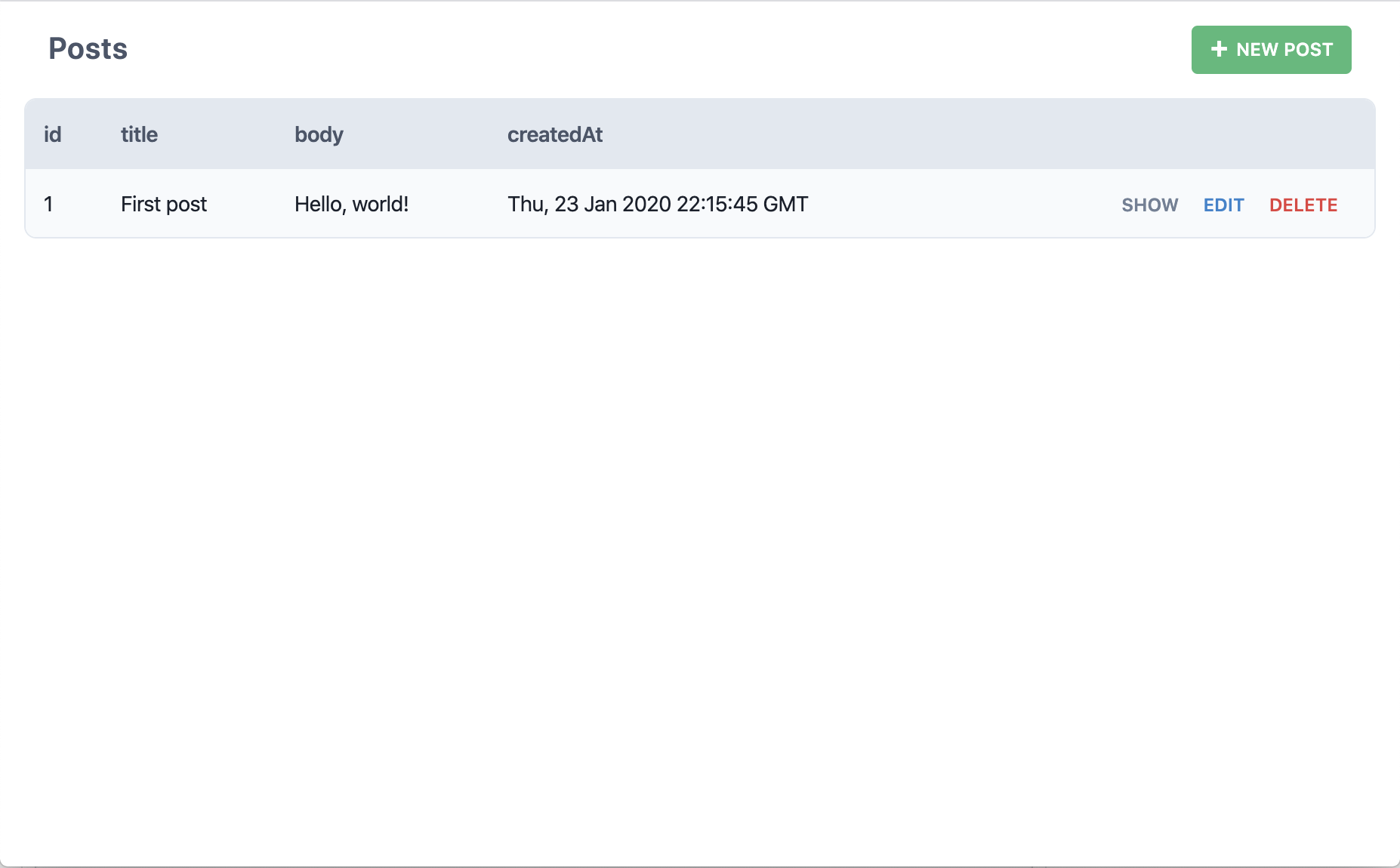
Venons-nous bien de créer un nouvel article? Exactement! Essayez-donc d'en créer d'autres.
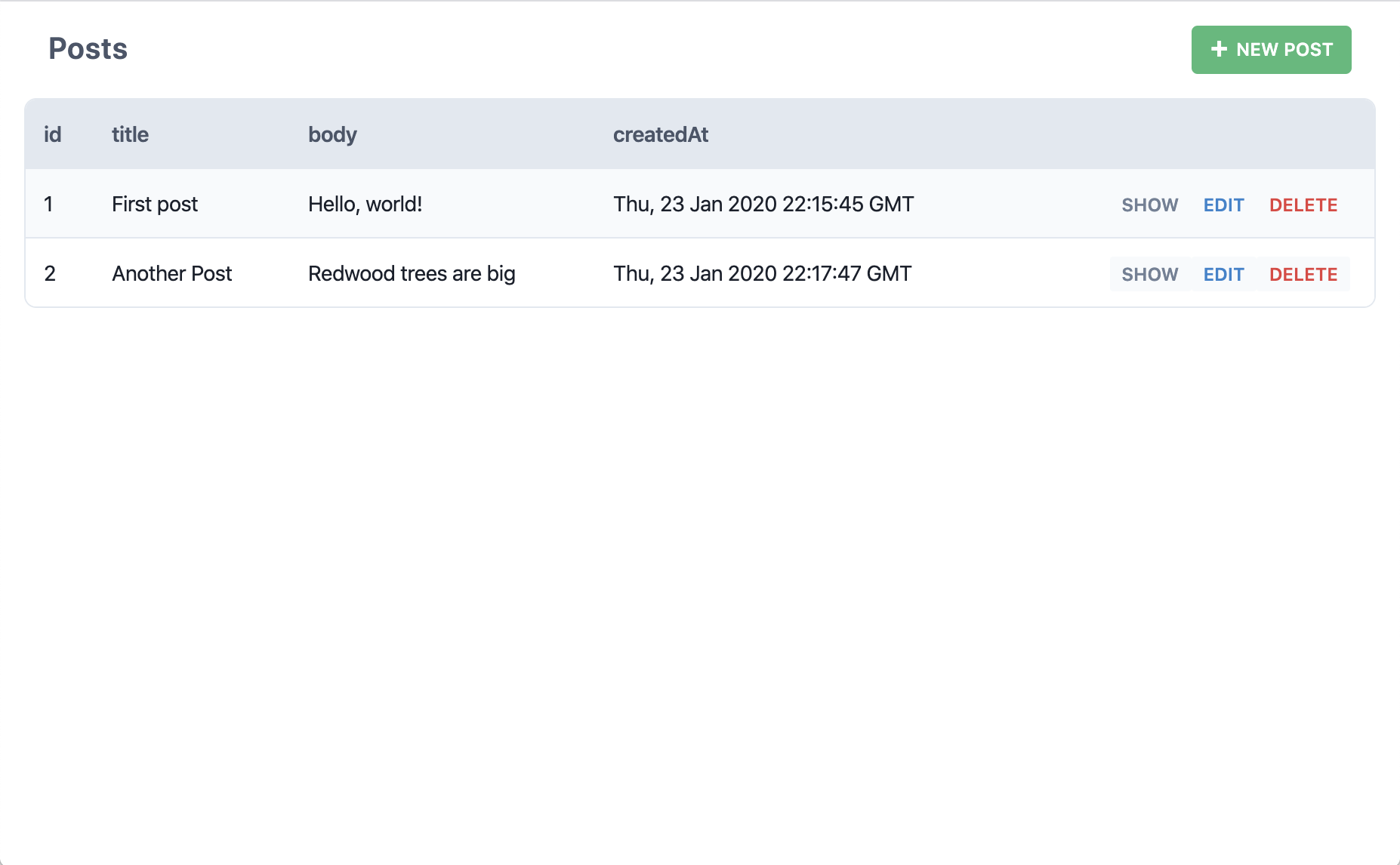
Et maintenant, que se passe-t-il lorsqu'on clique sur "Edit" (éditer) pour l'un de ces articles?
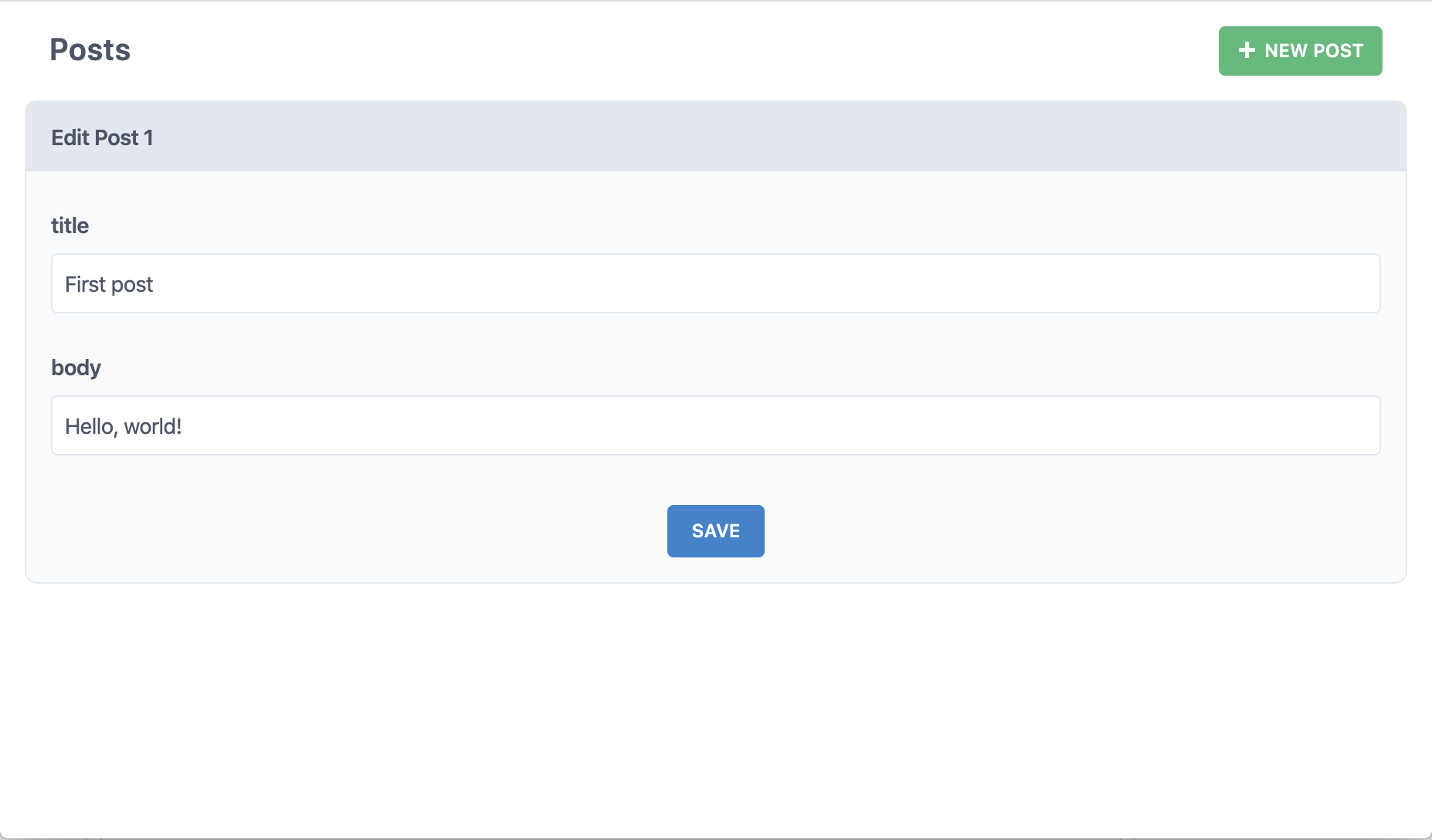
D'accord, et en cliquant sur le bouton "Delete" (supprimer)?
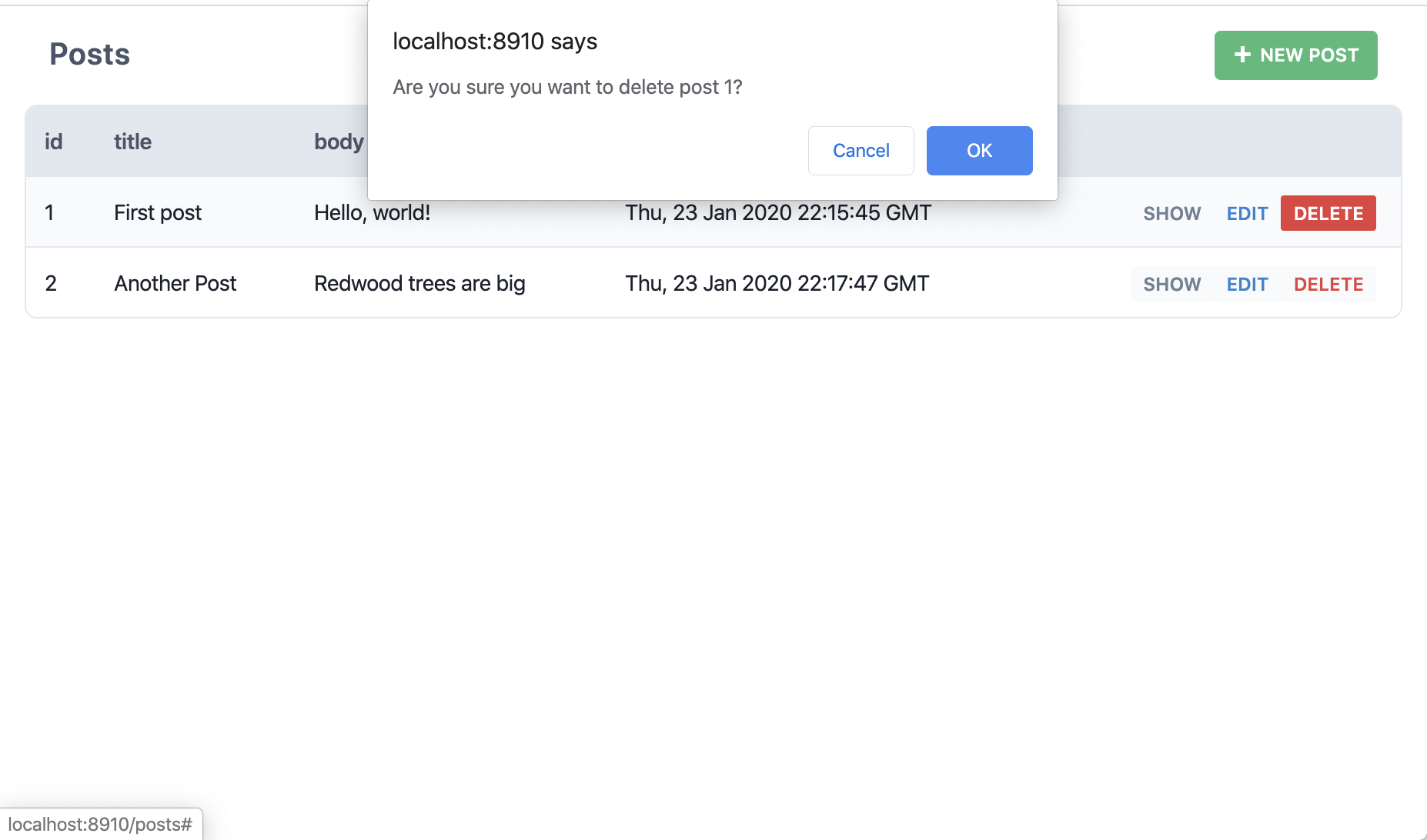
Oui c'est bien ça, en une seule commande, Redwood à créé l'ensemble des pages, composants et services nécessaires aux opérations usuelles de manipulation des articles. Pas même besoin d'ouvrir le gestionnaire de base de données. Redwood appelle ceci des scaffolds. Pas mal, non?
Voici dans le détail ce qui arrive lorsqu'on execute la commande yarn rw g scaffold post :
- Ajout d'un fichier SDL pour définir quelques requêtes et mutations GraphQL dans
api/src/graphql/posts.sdl.js - Ajout d'un fichier service
api/src/services/posts/posts.jsqui permet au client Javascript Prisma de manipuler la base de données - Ajout de quelques pages dans
web/src/pages:EditPostPagepour éditer un articleNewPostPagepour créer un nouvel articlePostPagepour montrer les détails d'un articlePostsPagepour lister tous les articles
- Ajout de routes pour ces nouvelles pages dans
web/src/Routes.js - Ajout de trois cells dans
web/src/components:EditPostCellcellule permettant de récupérer un article pour l'éditerPostCellcellule permettant de récupérer un article pour l'afficherPostsCellcellule permettant de récupérer tous les articles
- Ajout de quatre composants également dans
web/src/components:NewPostaffiche le formulaire permettant la création d'un nouvel articlePostaffiche un article en particulierPostFormle formulaire utilisé à la fois par les composants de création et d'édition d'un ariclePostsaffiche la table avec l'ensemble des articles
Générateurs et conventions de nommage
Vous remarquerez que certains fichiers générés ont un nom au pluriel, et d'autres au singulier. Cette convention est empruntée au framework Ruby on Rails. Lorsque vous avez à traiter d'un multiple de quelque chose (comme par exemple une liste d'articles), on utilisera le pluriel. Dans le cas contraire (par exemple la création d'un nouvel article), on utilisera le singulier. C'est aussi plus naturel lorsque l'on parle: "montre moi une liste d'articles" vs. "je vais créer un nouvel article".
Pour ce qui concerne les générateurs:
- Les fichiers de Services sont toujours au pluriel.
- Les méthodes dans les Services sont au singulier ou au pluriel selon qu'ils retournent plusieurs articles ou un seul article (
postsvs.createPost).- les fichiers SDL sont toujours au pluriel.
- Les pages générées par une commande de scaffold sont au pluriel ou au singulier selon que la page manipule plusieurs ou un seul article. Notez que lorsque vous utilisez vous-même un commande
pageen dehors d'un scaffold, le nom utilisé sera simplement celui que vous donnerez.- Les Layouts utilisent le nom que vous leur donnez
- Les composants et les cellules sont au pluriel ou au singulier selon le contexte lorsqu'ils sont générés par scaffolding. Dans le cas contraire, ils utilisent simplement le nom que vous leur donnez.
Remarquez également que seul le nom de la table en base de données et au singulier ou au pluriel, et pas le mot complet. Ainsi on a
PostsCell, et nonPostCells.Vous n'avez pas à suivre cette convention de façon obligatoire lorsque vous créez vos propres composants, pages, etc... Ceci étant nous vous le recommandons chaudement. Au bout du compte, la communauté Ruby on Rails a fini par s'attacher à cette convention, et ce même si au départ de nombreuses personnes s'y étaient opposées. "Give it five minutes" comme disent les anglo-saxons.
# Créer la page d'accueil
Nous pouvons commencer à remplacer ces pages les unes après les autres au fur et à mesure que l'équipe chargée du design nous donne des éléments, ou bien nous pouvons simplement les déplacer dnas la partie "administration" de notre site, et commencer à créer nos propres pages. Ceci étant, la partie publique du site ne va certainement pas autoriser les utilisateurs à créer, éditer ou supprimer les articles. Que peuvent donc faire les utilisateurs?
- Voir la liste des articles (sans liens pour éditer ou supprimer)
- Voir le détail d'un article
Puisque nous voudront probablement conserver un moyen de créer et éditer des articles plus tard, conservons les pages générées par scaffolding et créons-en de nouvelles pour ces deux cas de figure.
Nous avons déjà la HomePage, pas besoin de créer celle-ci donc. Nous souhaitons afficher une liste d'articles à l'utilisateur donc nous allons devoir ajouter ça. Nous avons besoin de récupérer le contenu depuis la base de données, et nous ne voulons pas que l'utilisateur soit face à une page blanche le temps du chargement (conditions réseau dégradées, serveur géographiquement distant, etc...), donc nous voudrons montrer une sorte de message de chargement et/ou une animation. D'autre part, si une erreur se produit, nous devrons faire en sorte de la prendre en charge. Enfin, nous devrons également prendre en compte le cas où le blog ne contient encore aucun article.
Wow... notre première page et il semble que nous ayons déjà à nous inquiéter de tant de choses... mais est-ce véritablement le cas ?